Introducing AutoSchemaKG: Autonomous Knowledge Graph Construction with Code Release
I’m excited to share our latest research paper and code release for AutoSchemaKG, a significant advancement in knowledge graph construction that eliminates the need for predefined schemas.
What is AutoSchemaKG?
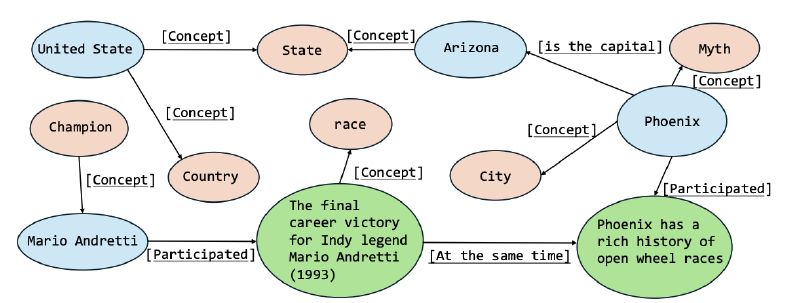
AutoSchemaKG leverages large language models to simultaneously extract knowledge triples and induce comprehensive schemas directly from text. Unlike traditional approaches that require domain experts to create predefined schemas, our system:
- Models both entities and events as first-class citizens
- Employs conceptualization to organize instances into semantic categories
- Scales to web-scale corpora without manual intervention
The ATLAS Knowledge Graphs
By applying our framework to the Dolma 1.7 corpus across three diverse subsets (Wikipedia, Semantic Scholar, and Common Crawl), we constructed the ATLAS family of knowledge graphs containing:
- 900+ million nodes
- 5.9 billion edges
- Billions of facts comparable in scale to parametric knowledge in LLMs
Key Results
Our experiments demonstrate that AutoSchemaKG:
- Achieves 95% semantic alignment with human-crafted schemas with zero manual intervention
- Outperforms state-of-the-art baselines by 12-18% on multi-hop question answering tasks
- Enhances large language model factuality by up to 9%
- Improves LLM performance on reasoning tasks across domains including Global Facts, History, Law, Religion, Philosophy, Medicine, and Social Sciences
Code and Resources Now Available!
We’ve released the complete implementation on GitHub at HKUST-KnowComp/AutoSchemaKG, along with a Python package to make it easier to use our technology in your own projects.
Getting Started
Install our package using pip after setting up the required dependencies:
|
|
Example Usage
The repository includes several example notebooks:
atlas_full_pipeline.ipynb: Build new knowledge graphs and implement RAGatlas_billion_kg_usage.ipynb: Host and use our billion-scale ATLAS knowledge graphsatlas_multihopqa.ipynb: Replicate our multi-hop QA evaluation results
Available Resources
- Paper: Read our research paper for technical details
- Code: Use our code on github
- Full Dataset: Download our complete dataset
- Neo4j CSV Dumps: Access our Neo4j database dumps via Huggingface Dataset
Why This Matters
This research represents a fundamental rethinking of knowledge graph construction, transforming what was once a heavily supervised process requiring significant domain expertise into a fully automated pipeline. This advancement not only accelerates KG development but also dramatically expands the potential application domains for knowledge-intensive AI systems.
We’re excited to see how the community will use AutoSchemaKG to build and leverage knowledge graphs without the traditional constraints of manual schema design!