Large Language Models (LLMs) have taken the world by storm. They can write code, draft emails, and answer complex questions. But they have a fundamental limitation: their knowledge is frozen in time, and they can sometimes “hallucinate” or make up facts.
A popular solution to this is Retrieval-Augmented Generation (RAG). The idea is simple: when you ask the LLM a question, a “retriever” first searches an external database (like Wikipedia or a company’s internal documents) for relevant information. This information is then passed to the LLM as context to help it generate a factual, up-to-date answer.
But RAG has its own challenges. The retrieval step can be slow, and feeding large amounts of context into the LLM for every single query is computationally expensive and increases latency. This is especially true when dealing with massive, complex knowledge sources like Knowledge Graphs (KGs), which store facts as interconnected triples (e.g., (Paris, capital_of, France)).
What if we could bake this knowledge directly into the model’s “brain” efficiently, without constant retrieval or massive context windows?
In our recent work, we introduce AtlasKV, a new framework that does exactly that. AtlasKV augments LLMs with billion-scale knowledge graphs, making them more knowledgeable and factually grounded, all while using a surprisingly small amount of GPU memory (less than 20GB for a KG with one billion facts).
The Secret Sauce: How AtlasKV Works
To understand AtlasKV’s breakthroughs, we first need to look at the new paradigm it builds upon. A promising direction for knowledge integration, pioneered by methods like KBLaM, involves plugging external knowledge directly into the LLM’s attention layers.
The core idea is to use a lightweight “Knowledge Adapter” (also called a projection head). This is a small, trainable set of parameters that acts as a universal translator. It learns to take key-value facts from an external source and project them into the specific representation space that the LLM’s attention mechanism understands. This is done while keeping the main LLM frozen, making it a very efficient way to teach the model new facts.
However, this innovative approach faced two major hurdles that prevented it from working at a massive scale:
- The Data Quality Problem: The method requires high-quality Query-Key-Value (Q-K-V) training data. Previous work relied on synthesizing this data from plain text using rigid templates, which resulted in limited query diversity and poor generalization. The model learned to answer specific question formats but struggled with the variety of questions seen in the real world.
- The Scalability Wall: The computation and memory costs grew linearly with the size of the knowledge base. While more efficient than other methods, this linear scaling still makes it prohibitively expensive to work with knowledge graphs containing hundreds of millions or billions of facts.
Our work, AtlasKV, is designed to solve these exact challenges, making this powerful parametric approach truly scalable and effective. We achieve this with two complementary innovations.
1. KG2KV: Speaking the LLM’s Native Language
The first challenge is getting the knowledge into a format the LLM can easily understand. An LLM’s core component is the self-attention mechanism, which works with Query, Key, and Value (Q-K-V) vectors.
Our KG2KV pipeline cleverly transforms each fact in a knowledge graph into this native Q-K-V format. For a triple like (John founded, cause, StockLemon.com), we can rephrase it as:
- Query: “What is the cause of John founding StockLemon.com?”
- Key: “the cause of John founded StockLemon.com”
- Value: “StockLemon.com”
This approach is far more powerful than previous methods that used rigid templates to create training data. By leveraging the rich and diverse relationships in a knowledge graph, we create high-quality, varied training data, from the ATLAS-Family KG we constructed in our previous work AutoSchemaKG, that helps the model generalize to new, unseen questions and topics.
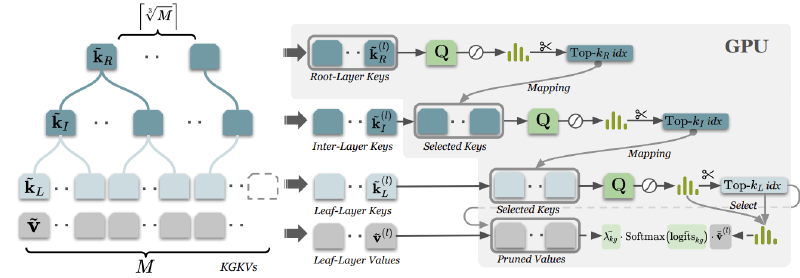
2. HiKVP: Finding a Needle in a Billion-Haystack Haystack
The second, and perhaps biggest, challenge is scalability. How do you give a model access to a billion facts without needing a supercomputer? Loading all one billion “keys” into GPU memory is impossible.
This is where our Hierarchical Key-Value Pruning (HiKVP) algorithm comes in. Instead of a flat, disorganized list of facts, HiKVP organizes the knowledge keys into a hierarchy, much like a library’s filing system.
When a query comes in, the model doesn’t search through every single fact. Instead, it performs a highly efficient, multi-step search:
- Root-Layer Search: It first looks at a small set of high-level “root” keys to find the general semantic area of the query.
- Inter-Layer Search: Based on the best matches from the root layer, it narrows the search down to a more specific set of “intermediate” keys.
- Leaf-Layer Search: Finally, it searches within this much smaller, highly relevant set of “leaf” keys to pinpoint the exact facts needed to answer the query.
This hierarchical pruning means that at any given moment, only a tiny fraction of the total knowledge base needs to be in the GPU’s active memory. This dramatically reduces both memory usage and computation time, changing the complexity from linear (O(M)) to sub-linear (O(∛M)), where M is the number of facts.
The Results: Unmatched Scalability and Accuracy
So, does it work? The results are striking.
Incredible Scalability: As shown in our experiments, while other methods see their memory usage explode as the knowledge graph grows, AtlasKV’s memory cost remains remarkably flat. We successfully augmented an LLM with a 1 billion triple KG using less than 20GB of VRAM—a task that is simply infeasible for other methods.
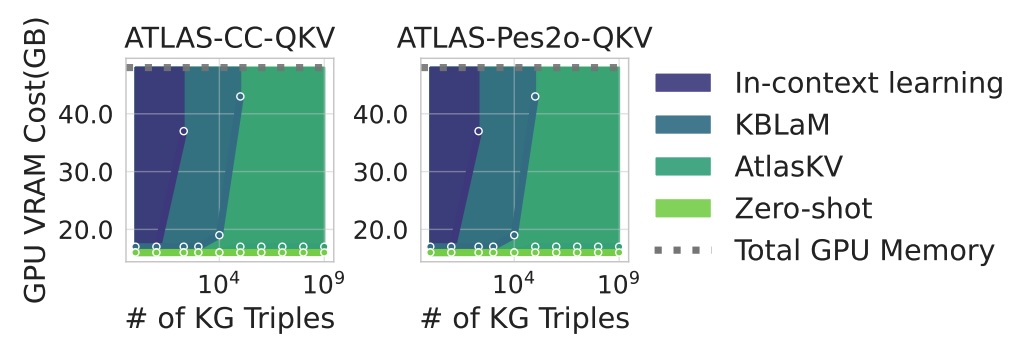
Superior Generalization and Accuracy: AtlasKV isn’t just more efficient; it’s smarter. Thanks to the high-quality training data from KG2KV, our model significantly outperforms baselines in both knowledge grounding accuracy and the relevance of its generated answers. It performs exceptionally well on out-of-distribution datasets—scenarios with complex questions and topics it has never seen during training.
Why This Matters
AtlasKV represents a major step forward in creating truly knowledgeable AI. By making it feasible to integrate massive, domain-specific knowledge graphs directly into LLMs on commodity hardware, we unlock a new class of applications:
- Enterprise AI: Imagine an assistant with perfect, instant recall of your company’s entire product catalog, support history, and internal processes.
- Scientific Research: A research assistant that has internalized all of PubMed or ArXiv, capable of answering complex questions and connecting disparate concepts.
- Fact-Grounded Chatbots: Customer service bots that provide accurate, reliable answers grounded in a comprehensive knowledge base, drastically reducing hallucinations.
We are excited about the future possibilities that AtlasKV enables and are committed to pushing the boundaries of what’s possible with knowledgeable, scalable, and efficient language models.
Interested in the technical details?
- Read the full paper on arXiv: https://www.arxiv.org/pdf/2510.17934
- Check out the source code: https://github.com/HKUST-KnowComp/AtlasKV;
- Check out the models: https://huggingface.co/collections/HaoyuHuang2/atlaskv
中文版
大语言模型现在非常有用。它们可以编写代码、起草邮件并回答复杂问题。但它们有一个根本性的限制:它们的知识是静态的,有时会"幻觉"或编造事实。
一个流行的解决方案是检索增强生成(RAG)。这个想法很简单:当你向LLM提问时,“检索器"首先在外部数据库(如Wikipedia或公司的内部文档)中搜索相关信息。然后这些信息作为上下文传递给LLM,帮助它生成真实、最新的答案。
但RAG也有自己的挑战。检索步骤可能很慢,而每次查询都将大量上下文输入LLM在计算上非常昂贵且会增加延迟。在处理大规模、复杂的知识源如**知识图谱(KG)**时尤其如此,它将以互连三元组(例如(Paris, capital_of, France))的形式存储事实。
如果我们能够高效地将这些知识直接融入模型的"大脑”,而不需要持续的检索或庞大的上下文窗口呢?
在我们最近的工作中,我们引入了AtlasKV,这是一个能够做到这一点的全新框架。AtlasKV用亿级知识图谱增强LLM,使它们更加知识渊博和基于事实,同时使用的GPU内存量出人意料地小(对于包含十亿个事实的知识图谱,不到20GB)。
核心方法:AtlasKV的工作原理
要理解AtlasKV的突破,我们首先需要了解它所构建的新范式。知识集成的一个有前景的方向,由KBLaM等方法开创,涉及将外部知识直接插入LLM的注意力层。
核心思想是使用一个轻量级的"知识适配器"。这是一小组可训练的参数,充当通用翻译器。它学会从外部源获取键值事实,并将它们投影到LLM注意力机制理解的特定表示空间。这是在主LLM保持冻结的情况下完成的,使其成为教模型新事实的一种非常高效的方法。
然而,这种创新方法面临两个主要障碍,阻碍了它在规模上的应用:
- 数据质量问题: 该方法需要高质量的查询-键-值(Q-K-V)训练数据。先前的工作依赖于使用死板的模板从纯文本合成这些数据,这导致查询多样性有限且泛化能力差。模型学会了回答特定的问题格式,但在处理现实世界中遇到的各种问题时遇到了困难。
- 可扩展性瓶颈: 计算和内存成本与知识库的大小呈线性增长。虽然比其他方法更高效,但这种线性扩展仍然使得处理包含数亿或数十亿事实的知识图谱变得昂贵得令人望而却步。
我们的工作AtlasKV旨在解决这些确切挑战,使这种强大的参数化方法真正具有可扩展性和有效性。我们通过两个互补的创新来实现。
1. KG2KV:使用LLM的底层语言,即向量表示。
第一个挑战是将知识转换为LLM可以轻松理解的格式。LLM的核心组件是自注意力机制,它与**查询、键和值(Q-K-V)**向量一起工作。
我们的KG2KV管道巧妙地将知识图谱中的每个事实转换为这种原生Q-K-V格式。对于像(John founded, cause, StockLemon.com)这样的三元组,我们可以将其重新表述为:
- 查询: “约翰创立StockLemon.com的原因是什么?”
- 键: “约翰创立StockLemon.com的原因”
- 值: “StockLemon.com”
这种方法比使用死板模板创建训练数据的先前方法强大得多。通过利用知识图谱中丰富多样的关系,我们从先前工作AutoSchemaKG中构建的ATLAS-Family KG创建高质量、多样化的训练数据,帮助模型泛化到新的、未见过的问题和主题。
2. HiKVP:在十亿数据大海捞针
第二个,也许也是最大的挑战是可扩展性。如何在不需要超级计算机的情况下给模型提供十亿个事实的访问权限?将所有十亿个"键"加载到GPU内存中是不可能的。
这就是我们的**分层键-值剪枝(HiKVP)**算法发挥作用的地方。HiKVP不是平铺的、杂乱无序的事实列表,而是将知识键组织成层次结构,很像图书馆的归档系统。
当查询到来时,模型不会搜索每个事实。相反,它执行高效的、多步骤搜索:
- 根层搜索: 它首先查看一小组高级"根"键以找到查询的一般语义区域。
- 中间层搜索: 基于根层的最佳匹配,它将搜索范围缩小到更具体的"中间"键集合。
- 叶层搜索: 最后,它在这个更小、高度相关的"叶"键集合中搜索,以精确定位回答查询所需的准确事实。
这种分层剪枝意味着在任何给定时刻,只有总知识库的一小部分需要在GPU的活动内存中。这极大地减少了内存使用和计算时间,将复杂度从线性(O(M))改变为次线性(O(∛M)),其中M是事实数量。
结果:无与伦比的可扩展性和准确性
那么,它有效吗?结果是显著的。
令人难以置信的可扩展性: 如我们的实验所示,虽然其他方法看到它们的记忆使用随知识图谱的增长而爆炸性增长,但AtlasKV的内存成本保持惊人地平稳。我们成功地用1亿三元组的KG使用不到20GB的VRAM增强了一个LLM——这对于其他方法来说简直是不可行的。
卓越的泛化和准确性: AtlasKV不仅更高效;它还更智能。得益于来自KG2KV的高质量训练数据,我们的模型在知识基础准确性和生成答案的相关性方面都显著优于基线。它在分布外数据集上表现异常出色——具有复杂问题和在训练期间从未见过的主题的场景。
为什么这很重要
AtlasKV代表了在创建真正有知识的AI方面向前迈出的一大步。通过使其可行在商用硬件上将大规模、特定领域的知识图谱直接集成到LLM中,我们开启了一类新的应用:
- 企业AI: 想象一个助手能够完美、即时地回忆您公司的整个产品目录、支持历史和内部流程。
- 科学研究: 一个已经内化了所有PubMed或ArXiv的研究助手,能够回答复杂问题并连接不同的概念。
- 基于事实的聊天机器人: 客户服务机器人提供准确、可靠的答案,基于全面的知识库,大大减少幻觉。
我们对AtlasKV实现的未来可能性感到兴奋,并致力于推动有知识、可扩展和高效的语言模型可能的边界。