TERAG: Making High-Performance Graph RAG Affordable and Scalable
Retrieval-Augmented Generation (RAG) has been a game-changer for Large Language Models (LLMs), helping them fight off “hallucinations” and ground their answers in real-world facts. The next frontier in this space is Graph-based RAG, which uses knowledge graphs to understand the complex relationships between pieces of information. This allows for more sophisticated reasoning, especially for multi-hop questions that require connecting multiple dots.
Systems like Microsoft’s GraphRAG have shown incredible promise, delivering highly accurate and transparent answers. But there’s a giant elephant in the room: the cost.
Building these powerful knowledge graphs often requires extensive use of LLMs to extract entities, define relationships, and summarize information. This process consumes an enormous number of tokens. To put it in perspective, one recent estimate suggested that indexing just 5GB of legal documents could cost as much as $33,000. This prohibitive cost is a major barrier, preventing many organizations from adopting Graph RAG at scale.
This is the problem we set out to solve with our new paper, “TERAG: Token-Efficient Graph-Based Retrieval-Augmented Generation.” We asked ourselves: can we achieve the power of Graph RAG without the crippling price tag?
Our answer is a resounding yes.
The Problem: Why is Graph RAG So Expensive?
The magic of Graph RAG lies in its indexing pipeline, where it transforms mountains of unstructured text into a structured knowledge graph. State-of-the-art methods rely heavily on LLMs for this construction. They use multiple, complex prompts to:
- Extract entities (people, places, concepts).
- Define the relationships between them as
(subject, relation, object)triplets. - Generate summaries for nodes or even entire clusters of information.
While this creates a rich, detailed graph, each step is an expensive LLM call. When you’re processing millions of documents, the token consumption—and the cost—skyrockets.
Our Solution: The TERAG Framework
TERAG is a simple yet effective framework designed from the ground up for token efficiency. Instead of using LLMs for every step, we minimize their role to only what’s essential, leveraging faster, non-LLM methods for the heavy lifting.
Our pipeline is straightforward:
1. Lightweight Concept Extraction (The Only LLM Step in Construction)
Instead of complex, multi-stage extraction, we use a single pass with a carefully designed few-shot prompt. The LLM is asked to do just two things:
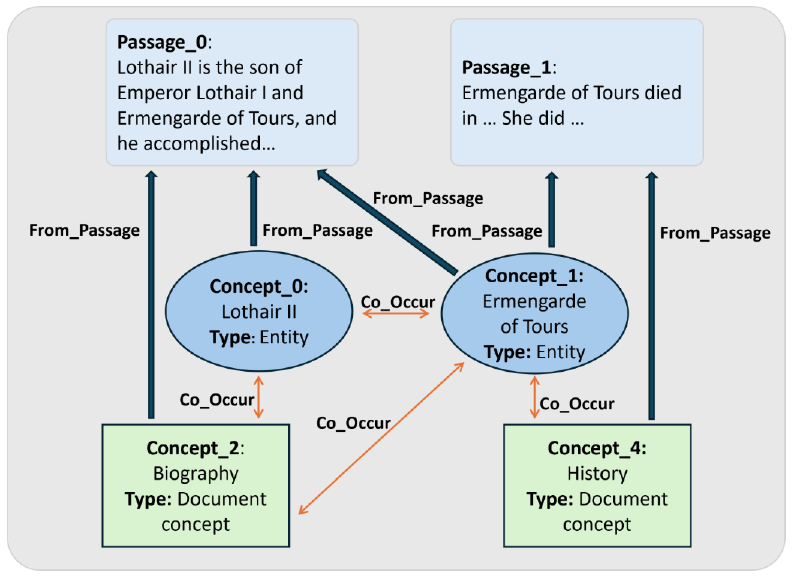
- Extract Named Entities: Identify proper nouns like “Lothair II” or “MuSiQue”.
- Extract Document-Level Concepts: Pull out the main ideas or themes of a passage.
To further cut costs, we instruct the LLM to output only the raw text of the concepts, not bulky JSON. This simple change drastically reduces the number of expensive output tokens.
2. Efficient, Non-LLM Graph Construction
With the concepts extracted, we build the graph using simple, deterministic rules—no LLMs required.
- Nodes: The graph has two types of nodes: Passage nodes (representing the original text chunks) and Concept nodes (the entities and ideas we just extracted).
- Edges: We create two simple types of connections:
has passage: An edge from a concept to the passage it came from. This preserves the source of the information.co-occurrence: An edge between two concepts if they appear in the same passage. This builds a web of contextual relationships.
The result is an elegant, effective knowledge graph built at a fraction of the cost.
 Overall pipeline of the proposed TERAG framework. The process consists of lightweight concept extraction with LLMs, followed by efficient non-LLM clustering and graph construction.
Overall pipeline of the proposed TERAG framework. The process consists of lightweight concept extraction with LLMs, followed by efficient non-LLM clustering and graph construction.
3. Smart Retrieval with Personalized PageRank (PPR)
During retrieval, we continue our token-efficient approach. The LLM is used only for a quick task: extracting named entities from the user’s query. These entities are then mapped to nodes in our graph.
We then use Personalized PageRank (PPR), a powerful graph traversal algorithm, to find the most relevant passages. The “personalization” comes from biasing the algorithm to start from the nodes related to the user’s query. This allows us to explore the graph and find connected information that simple semantic search would miss. Finally, the top-ranked passages are sent to a powerful reader LLM to generate the final answer.
The Results: Massive Savings, Competitive Performance
So, how does this lightweight approach stack up? The results speak for themselves.
Astonishing Token Efficiency
TERAG is radically more efficient than existing methods. Compared to other popular graph-based RAG systems, TERAG reduces output token consumption by a staggering 89-97%.
| Method | Relative Output Tokens (TERAG = 100%) |
|---|---|
| TERAG (Ours) | 100% |
| AutoSchemaKG | 861% - 1,160% |
| LightRAG | 1,041% - 2,753% |
| MiniRAG | 1,602% - 4,145% |
This is a critical advantage because output tokens are generated sequentially and are significantly more computationally expensive than input tokens. This efficiency makes TERAG a practical solution for real-world, large-scale deployment.
Highly Competitive Accuracy
You might think that such drastic cost savings must come with a major hit to accuracy. But TERAG holds its own. On standard multi-hop QA benchmarks like 2WikiMultihopQA, MuSiQue, and HotpotQA, TERAG achieves highly competitive performance.
We set a pragmatic goal: to achieve at least 80% of the accuracy of a powerful baseline (AutoSchemaKG + HippoRAG). TERAG successfully met this target across all datasets. In fact, on the 2Wiki dataset, TERAG’s accuracy is nearly identical to that of the widely-used GraphRAG, while being orders of magnitude cheaper.
The chart below visualizes the trade-off between accuracy (EM score) and cost (output tokens) on the 2Wiki dataset. The ideal spot is the top-left: high accuracy for low cost. TERAG is the clear winner in the efficiency-performance balance.
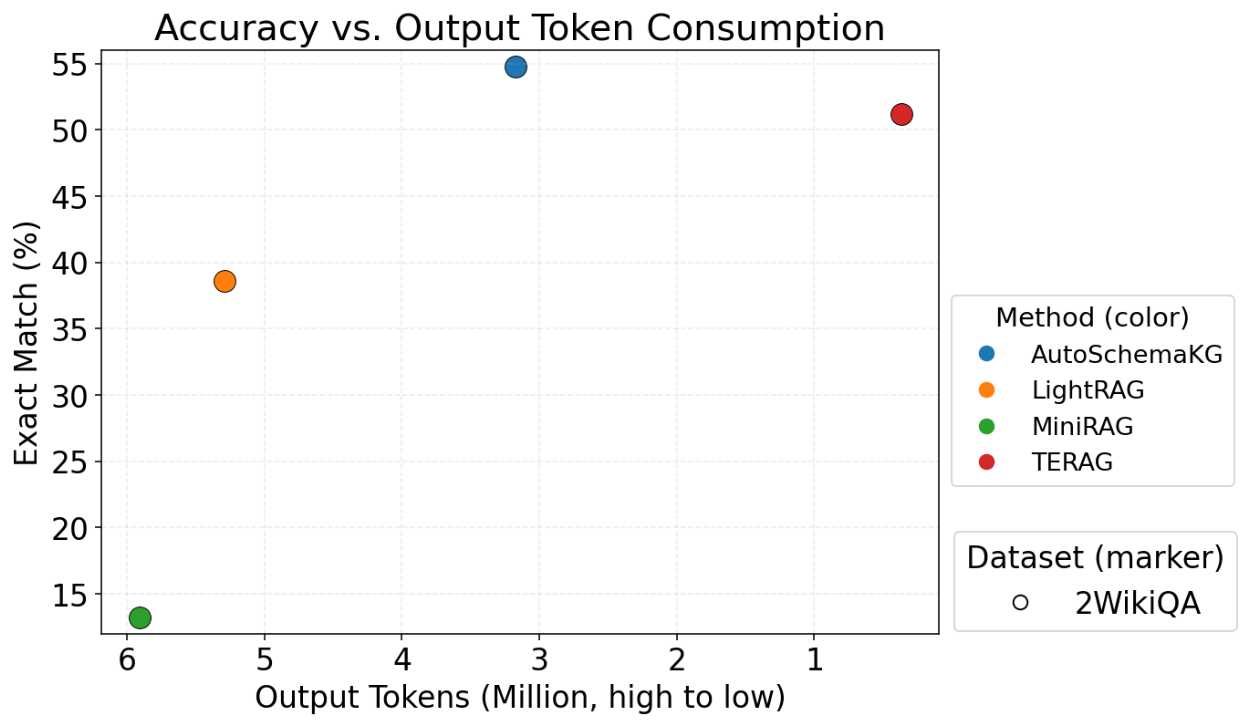 (Accuracy vs. Output Token Consumption on the 2Wiki Dataset)
(Accuracy vs. Output Token Consumption on the 2Wiki Dataset)
Why This Matters
TERAG demonstrates that you don’t need to throw endless compute at a problem to get great results. By being smart and targeted in our use of LLMs, we can build powerful, scalable, and—most importantly—affordable Graph RAG systems.
This work opens the door for:
- Democratizing Graph RAG: Making it accessible to startups, researchers, and organizations without massive budgets.
- Large-Scale Deployment: Enabling companies to apply Graph RAG to their entire document corpus, not just small samples.
- Cost-Sensitive Applications: Unlocking new use cases where real-time performance and low operational costs are critical.
Conclusion and Next Steps
We believe TERAG offers a pragmatic and powerful path forward for the RAG community. It proves that a carefully designed, lightweight pipeline can deliver a far better balance between cost and performance than heavyweight, LLM-centric approaches.
We are already exploring future work, including extracting concepts with controllable granularity to build even richer, multi-layered graphs.
We invite you to dive deeper into our methodology and results by reading the full paper.
Read the full paper on arXiv: https://arxiv.org/pdf/2509.18667
Code is available at: https://github.com/wocqcm2/TERAG